1、前言
Volcano是一个基于Kubernetes构建的批处理系统,它提供了许多批处理和弹性工作负载通常需要的一套机制,主要用于高性能计算场景,包括机器学习、深度学习、大数据应用等。本文接下来主要从源码层面分析volcano的调度机制。
2、搭建环境
本文使用Volcano 1.9版本搭建运行环境,在运行volcano前需要先搭建好k8s集群,搭建方式可参考这篇文章:http://www.miaozhouguang.com/?p=490。执行如下命令即可启动volcano 1.9版本服务:
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/release-1.9/installer/volcano-development.yaml
执行后会自动下载如下镜像:
volcanosh/vc-controller-manager:v1.9.0 volcanosh/vc-scheduler:v1.9.0 volcanosh/vc-webhook-manager:v1.9.0
命名空间:
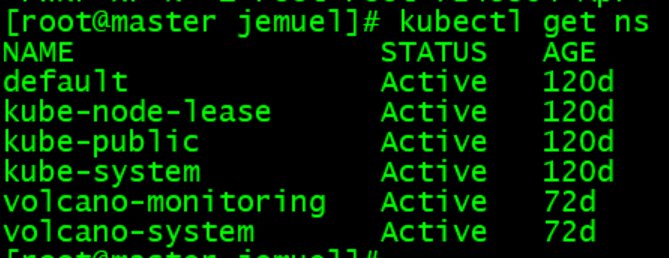
调度服务:

配置文件:

调度配置:
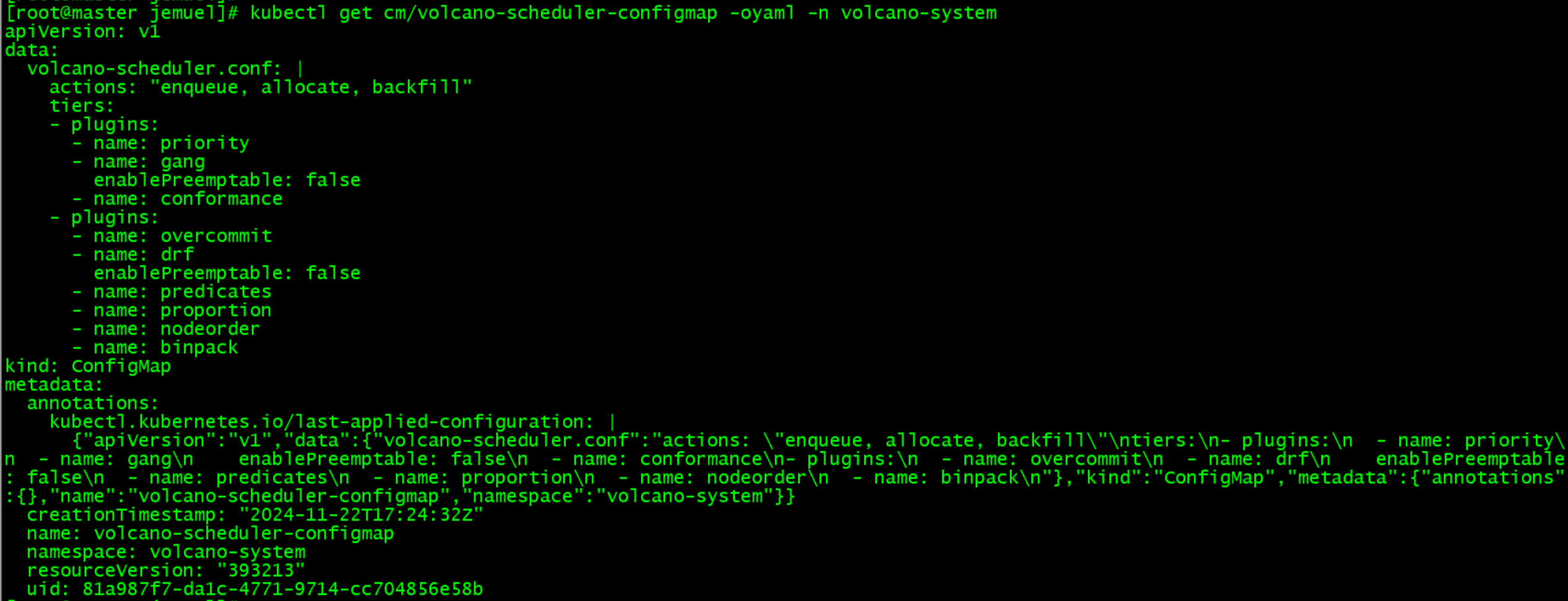
调度器的核心服务是volcano-scheduler,本文重点分析该服务的主要功能,既然从源码层面进行分析,就需要调试环境,我们可以将k8s集群中的volcano-scheduler deployment删除,启动本地volcano-scheduler进行调试,具体可参考这篇文章中调试k8s默认调度器的方式:http://www.miaozhouguang.com/?p=490。
3、执行流程
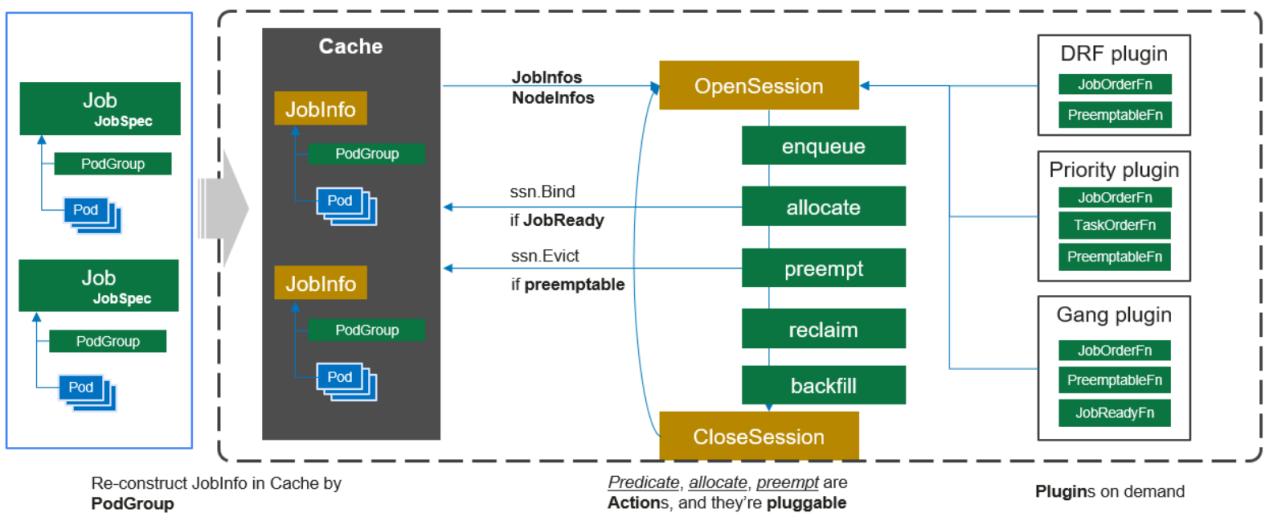
Volcano调度器整体执行步骤:
(1)客户端提交的Job被scheduler观察到并缓存起来。
(2)周期性的开启会话,一个调度周期开始。
(3)将没有被调度的Job发送到会话的待调度队列中。
(4)遍历所有的待调度Job,按照定义的次序依次执行enqueue、allocate、preempt、reclaim、backfill等动作,为每个Job找到一个最合适的节点。将该Job 绑定到这个节点。action中执行的具体算法逻辑取决于注册的plugin中各函数的实现。
(5)关闭本次会话。
4、数据结构
Volcano中各数据结构关系总览如下:
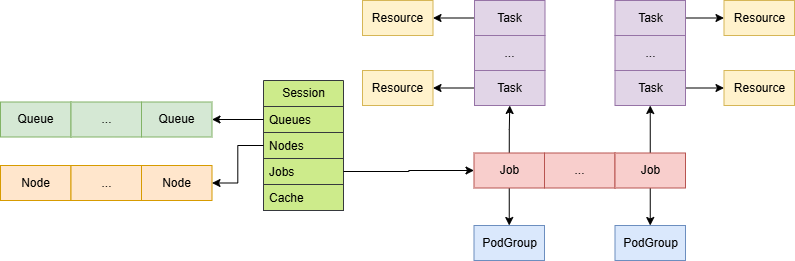
Session:表示每轮调度会话,其中包含了会话过程中所有信息,如Queue、Node、Job等;
Queue:表示任务队列,提交的任务都会绑定到指定Queue中执行;
Node:表示集群节点信息;
Job:表示提交的任务组,包含一组相关的子任务,任务组和PodGroup一一对应;
Task:表示任务组中子任务,和Pod一一对应;
Resource:表示资源信息,如CPU、内存、GPU等。
4.1 Scheduler
type PluginOption struct {
//插件名称
Name string `yaml:"name"`
//是否启用jobOrderFn
EnabledJobOrder *bool `yaml:"enableJobOrder"`
//是否启用分层
EnabledHierarchy *bool `yaml:"enableHierarchy"`
//是否启用jobReadyFn
EnabledJobReady *bool `yaml:"enableJobReady"`
//是否启用jobPipelinedFn
EnabledJobPipelined *bool `yaml:"enableJobPipelined"`
//是否启用taskOrderFn
EnabledTaskOrder *bool `yaml:"enableTaskOrder"`
//是否启用preemptableFn
EnabledPreemptable *bool `yaml:"enablePreemptable"`
//是否启用reclaimableFn
EnabledReclaimable *bool `yaml:"enableReclaimable"`
//是否启用preemptiveFn
EnablePreemptive *bool `yaml:"enablePreemptive"`
//是否启用queueOrderFn
EnabledQueueOrder *bool `yaml:"enableQueueOrder"`
//是否启用clusterOrderFn
EnabledClusterOrder *bool `yaml:"EnabledClusterOrder"`
//是否启用predicateFn
EnabledPredicate *bool `yaml:"enablePredicate"`
//是否启用bestNodeFn
EnabledBestNode *bool `yaml:"enableBestNode"`
//是否启用nodeOrderFn
EnabledNodeOrder *bool `yaml:"enableNodeOrder"`
//是否启用targetJobFn
EnabledTargetJob *bool `yaml:"enableTargetJob"`
//是否启用reservedNodesFn
EnabledReservedNodes *bool `yaml:"enableReservedNodes"`
//是否启用jobEnqueuedFn
EnabledJobEnqueued *bool `yaml:"enableJobEnqueued"`
//是否启用victimsFn
EnabledVictim *bool `yaml:"enabledVictim"`
//是否启用jobStarvingFn
EnabledJobStarving *bool `yaml:"enableJobStarving"`
//是否启用overusedFn
EnabledOverused *bool `yaml:"enabledOverused"`
//是否启用allocatable
EnabledAllocatable *bool `yaml:"enabledAllocatable"`
//插件执行需要的参数
Arguments map[string]interface{} `yaml:"arguments"`
}
type Tier struct {
Plugins []PluginOption `yaml:"plugins"`
}
type Scheduler struct {
cache schedcache.Cache //集群缓存信息
schedulerConf string //配置文件路径
fileWatcher filewatcher.FileWatcher //配置文件监听器
schedulePeriod time.Duration //调度循环间隔,默认1s
mutex sync.Mutex
actions []framework.Action //Action列表
plugins []conf.Tier //Plugin列表
...
}
Scheduler定义了调度器相关信息,包括缓存、配置、Action、Plugin等,程序启动时进行初始化,每次调度循环会间隔schedulePeriod执行其runOnce函数进行调度任务。
4.2 Session
type Session struct {
UID types.UID //会话ID
cache cache.Cache //集群缓存信息,包括节点、队列、任务等
TotalResource *api.Resource //当前所有节点资源总量
Jobs map[api.JobID]*api.JobInfo //当前所有任务信息
Nodes map[string]*api.NodeInfo //当前所有节点信息
Queues map[api.QueueID]*api.QueueInfo //当前所有队列信息
NamespaceInfo map[api.NamespaceName]*api.NamespaceInfo //当前所有namespace信息
plugins map[string]Plugin //当前所有插件信息
jobOrderFns map[string]api.CompareFn //job对比函数,用于优先级排序
queueOrderFns map[string]api.CompareFn //queue对比函数,用于优先级排序
taskOrderFns map[string]api.CompareFn //task对比函数,用于优先级排序
...
}
Session定义了执行调度的会话数据,每轮调度循环执行前会创建Session对象,该对象会从Cache中获取当前集群的快照信息,包括节点信息、任务信息、队列信息等,所有action、plugin执行都在session上下文中,调度完成后关闭session。
4.3 Queue
//队列CRD类型
type Queue struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec QueueSpec
Status QueueStatus
}
type QueueSpec struct {
Weight int32 //队列权重
Capability v1.ResourceList //队列资源容量
Reclaimable *bool //是否可被其他队列抢占资源
ExtendClusters []Cluster //队列中job分发的集群列表
Guarantee Guarantee //队列资源预留量
Affinity *Affinity //设置队列的NodeGroup亲和性、反亲和性规则
Type string //队列类型
Parent string //父队列
Deserved v1.ResourceList //队列应分配资源量,能被其他队列共享
}
type QueueStatus struct {
State QueueState //队列状态
Unknown int32 //Unknown状态PodGroup数量
Pending int32 //Pending状态PodGroup数量
Running int32 //Running状态PodGroup数量
Inqueue int32 //Inqueue状态PodGroup数量
Completed int32 //Completed状态PodGroup数量
Reservation Reservation //队列预留资源量
Allocated v1.ResourceList //队列已分配资源量
}
//队列Go数据结构
type QueueInfo struct {
UID QueueID //队列ID
Name string //队列名
Weight int32 //队列权重,用于计算队列资源分配
Weights string //分层队列权重,使用/分隔,在drf插件中使用
Hierarchy string //分层队列名,使用/分隔,在drf插件中使用
Queue *scheduling.Queue //队列 CRD类型
}
QueueInfo定义了任务队列数据结构,包括运行资源相关信息,如队列权重、资源容量、是否可被抢占等,提交的任务需要绑定到队列运行。
队列状态如下:
- QueueStateOpen = "Open" //开启
- QueueStateClosed = "Closed" //关闭
- QueueStateClosing = "Closing" //关闭中
- QueueStateUnknown = "Unknown" //未知
4.4 Node
type NodeInfo struct {
Name string //节点名称
Node *v1.Node //对应k8s Node
State NodeState //节点状态
Releasing *Resource //节点上即将释放的资源
Idle *Resource //节点空闲资源
Used *Resource //节点已使用的资源,包括running、terminating pod
Allocatable *Resource //可分配资源
Capacity *Resource //资源总量
Tasks map[TaskID]*TaskInfo //节点上任务列表
...
}
NodeInfo定义了节点数据结构,对应到k8s中一个节点,包括状态、资源使用情况等信息,volcano内部监听k8s集群节点变化,将节点信息进行缓存。
4.5 Task
//调度上下文
type TransactionContext struct {
NodeName string //节点名
Status TaskStatus //task状态
}
type TaskInfo struct {
UID TaskID //task ID,对应pod uid
Job JobID //job ID
Name string //名称
Namespace string //命名空间
Resreq *Resource //task运行时使用资源量
InitResreq *Resource //task启动时使用资源量
TransactionContext //调度上下文
LastTransaction *TransactionContext //上一轮调度上下文
Priority int32 //task优先级
Preemptable bool //task是否可被抢占
BestEffort bool //未指定资源申请量,如未设置requests
Pod *v1.Pod //对应k8s pod
...
}
TaskInfo定义了子任务数据结构,对应到k8s中一个pod,包括状态、请求资源、优先级等信息。
Task状态如下:
- Pending = 1 //表示task在apiserver处于pending状态
- Allocated = 2 //表示调度器已经分配了机器
- Pipelined = 4 //表示调度器已经分配了机器,并且在等待释放资源
- Binding = 8 //表示调度器发送绑定请求到apiserver
- Bound = 16 //表示task已经绑定到机器
- Running = 32 //表示task正在运行
- Releasing = 64 //表示task已经被删除
- Succeeded = 128 //表示task成功结束
- Failed = 256 //表示task失败结束
- Unknown = 512 //未知状态
4.6 Job
type tasksMap map[TaskID]*TaskInfo
type JobInfo struct {
UID JobID //任务ID,格式:PodGroup.Namespace/PodGroup.Name
PgUID types.UID //对应PodGroup UID
Name string //名称,等于PodGroup.Name
Namespace string //命名空间,等于PodGroup.Namespace
Queue QueueID //队列名称
Priority int32 //优先级
MinAvailable int32 //执行job所需最小task数
WaitingTime *time.Duration //job入队最长等待时间,从创建时刻开始
TaskStatusIndex map[TaskStatus]tasksMap //task状态索引,tasksMap中key为task uid
Tasks tasksMap //task列表,tasksMap中key为task uid
TaskMinAvailable map[TaskID]int32 //对应每个task的minAvailable,key为pod annotations中volcano.sh/task-spec的值
TaskMinAvailableTotal int32 //所有task minAvailable总和
Allocated *Resource //已分配资源量
TotalRequest *Resource //总请求资源量
PodGroup *PodGroup //对应PodGroup CRD
Preemptable bool //job是否可被抢占
...
}
JobInfo定义了任务组数据结构,包含一个或多个task,对应到k8s中一个PodGroup,包括队列、子任务、优先级等信息。
注意:TaskStatusIndex、Tasks中tasksMap的key是task uid,即对应pod的uid,而TaskMinAvailable中key对应的是pod的annotations的volcano.sh/task-spec取值,两者是不同的。
job各种状态计算函数如下:
- ReadyTaskNum:计算ready task数量,统计job中状态为Bound、Binding、Running、Allocated、Succeeded的task总数。
- WaitingTaskNum:计算waiting task数量,统计job中状态为Pipelined的task数量。
- PendingBestEffortTaskNum:计算Pending BestEffort数量,统计job中状态为Pending且BestEffort为true的task数量。
- CheckTaskValid:校验每个task有效性,统计job中状态为Bound、Binding、Running、Allocated、Succeeded、Pipelined、Pending的task各分类数量,比较统计值是否不小于job.TaskMinAvailable中各分类数量大小。
- CheckTaskReady:校验每个task是否ready,统计job中状态为Bound、Binding、Running、Allocated、Succeeded、Pending且启动资源为空的task各分类数量,比较统计值是否不小于job.TaskMinAvailable中各分类数量大小。
- CheckTaskPipelined:校验每个task是否处于pipelined状态,统计job中状态为Bound、Binding、Running、Allocated、Succeeded、Pipelined、Pending且启动资源为空的task各分类数量,比较统计值是否不小于job.TaskMinAvailable中各分类数量大小。
- CheckTaskStarving:校验每个task是否饥饿,统计job中状态为Bound、Binding、Running、Allocated、Succeeded、Pipelined的task各分类数量,比较统计值是否不小于job.TaskMinAvailable中各分类数量大小。
- ValidTaskNum:计算有效task数量,统计job中状态为Bound、Binding、Running、Allocated、Succeeded、Pipelined、Pending的task总数。
- IsReady:判断job是否ready,比较函数ReadyTaskNum、PendingBestEffortTaskNum之和是否不小于job.MinAvailable。
- IsPipelined:判断job是否处于pipelined状态,比较函数WaitingTaskNum、ReadyTaskNum、PendingBestEffortTaskNum之和是否不小于job.MinAvailable。
- IsStarving:判断job是否饥饿,比较函数WaitingTaskNum、ReadyTaskNum之和是否小于job.MinAvailable。
- IsPending:判断job是否pending,判断对应PodGroup的Phase为Pending。
4.7 PodGroup
type PodGroupSpec struct {
MinMember int32 //执行PodGroup所需的最小task数量,作为总体判断,如果资源不满足,PodGroup不会被调度
MinTaskMember map[string]int32 //执行每个task所需的最小pod数量,如master 1个、worker 3个,如果资源不满足,PodGroup不会被调度
Queue string //定义PodGroup所在queue,用于分配资源,如果queue不存在,PodGroup不会被调度
PriorityClassName string //指定PodGroup的优先级
MinResources *v1.ResourceList //执行PodGroup所需的最小资源,如果不满足,PodGroup不会被调度
}
type PodGroupStatus struct {
Phase PodGroupPhase //当前PodGroup的状态
Conditions []PodGroupCondition //PodGroup的condition
Running int32 //运行中的pod数
Succeeded int32 //成功的pod数
Failed int32 //失败的pod数
}
//PodGroup CRD类型
type PodGroup struct {
metav1.TypeMeta
metav1.ObjectMeta
Spec PodGroupSpec
Status PodGroupStatus
}
PodGroup定义了k8s CRD结构,对应一个job。
PodGroup状态如下:
- PodGroupPending = "Pending" //PodGroup已被系统接收,调度器还未分配资源
- PodGroupRunning = "Running" //PodGroup中至少minMember个pod进入运行状态
- PodGroupUnknown = "Unknown" //PodGroup中少于minMember个pod在运行,其余pod未被调度,等待控制器恢复
- PodGroupInqueue = "Inqueue"//介于Pending、Running之间,表示可以开始创建pod
- PodGroupCompleted = "Completed" //PodGroup中所有pod已完成
4.8 Resource
type Resource struct {
MilliCPU float64 //CPU资源
Memory float64 //内存资源
ScalarResources map[v1.ResourceName]float64 //其他资源,如GPU
...
}
Resource定义了资源结构,所有资源相关的操作都是基于该结构进行。
4.9 Action
type Action interface {
Name() string //action名称
Initialize() //初始化action
Execute(ssn *Session) //执行action
UnInitialize() //action后处理
}
Action定义了操作接口,所有操作实现该接口,调度器启动时会从配置文件读取操作列表,执行每轮调度循环时,会依次执行所配置操作的Execute函数。
4.10 Plugin
type Plugin interface {
Name() string //名称
OnSessionOpen(ssn *Session) //启动会话执行
OnSessionClose(ssn *Session) //关闭会话执行
}
Plugin定义了插件接口,所有插件实现该接口,调度器启动时会从配置文件读取配置的插件及参数,执行每轮调度循环并启动会话时会依次执行插件的OnSessionOpen函数,该函数会进行插件初始化,并注册回调函数,用于Action执行过程中使用。
4.11 Cache
type SchedulerCache struct {
sync.Mutex
kubeClient kubernetes.Interface
//资源监听对象
podInformer infov1.PodInformer
nodeInformer infov1.NodeInformer
podGroupInformerV1beta1 vcinformerv1.PodGroupInformer
queueInformerV1beta1 vcinformerv1.QueueInformer
pvInformer infov1.PersistentVolumeInformer
pvcInformer infov1.PersistentVolumeClaimInformer
scInformer storagev1.StorageClassInformer
pcInformer schedv1.PriorityClassInformer
quotaInformer infov1.ResourceQuotaInformer
csiNodeInformer storagev1.CSINodeInformer
csiDriverInformer storagev1.CSIDriverInformer
csiStorageCapacityInformer storagev1beta1.CSIStorageCapacityInformer
cpuInformer cpuinformerv1.NumatopologyInformer
//资源缓存
Jobs map[schedulingapi.JobID]*schedulingapi.JobInfo
Nodes map[string]*schedulingapi.NodeInfo
Queues map[schedulingapi.QueueID]*schedulingapi.QueueInfo
PriorityClasses map[string]*schedulingv1.PriorityClass
NodeList []string
defaultPriorityClass *schedulingv1.PriorityClass
defaultPriority int32
CSINodesStatus map[string]*schedulingapi.CSINodeStatusInfo
NamespaceCollection map[string]*schedulingapi.NamespaceCollection
...
}
SchedulerCache定义了缓存数据结构,缓存了k8s中各类资源对象,包括node、job、queue等,缓存对象在调度器启动时初始化,之后采用监听集群资源变化方式更新缓存。
5、Action
Action是每轮调度中执行的动作,按配置顺序依次执行,主要包括任务入队、分配资源、任务抢占等,Action执行过程中会调用各种扩展点函数,各类插件启动时注册自己的扩展点函数,从而达到通过不同插件影响Action运行逻辑。
5.1 enqueue
enqueue依次获取高优先级queue、高优先级Pending job,判断job是否满足运行条件,如果满足则设置对应PodGroup的状态为Inqueue。
执行流程图如下:
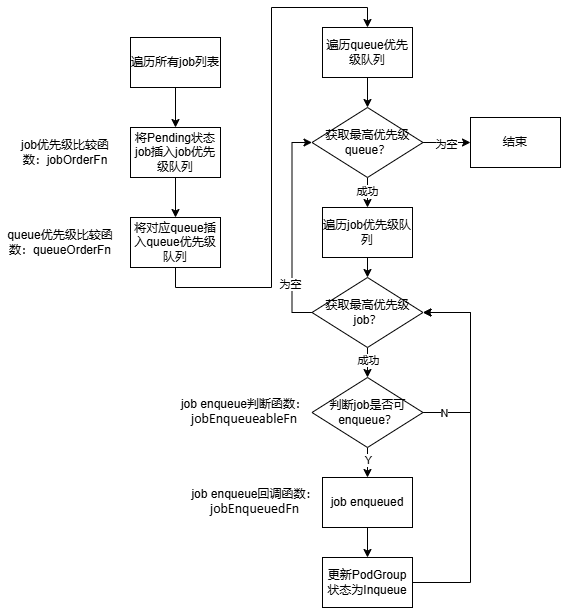
执行步骤:
(1)遍历当前集群中所有job,将Pending状态的job加入待处理优先级队列中;
(2)依次获取高优先级queue,并从queue中依次获取高优先级job;
(3)判断job是否能够enqueue,能enqueue则设置对应PodGroup状态为Inqueue。
涉及相关插件如下:
(1)queue优先级比较函数为queueOrderFn,注册的插件有:capacity、drf、proportion。
(2)job优先级比较函数为jobOrderFn,注册的插件有:sla、drf、gang、priority、tdm。
(3)判断job是否可enqueue函数为jobEnqueueableFn,注册的插件有:overcommit、capacity、extender、proportion、resourcequota、sla。
5.2 allocate
allocate依次为高优先级queue、高优先级Inqueue job中所有task分配最佳node。
执行流程图如下:
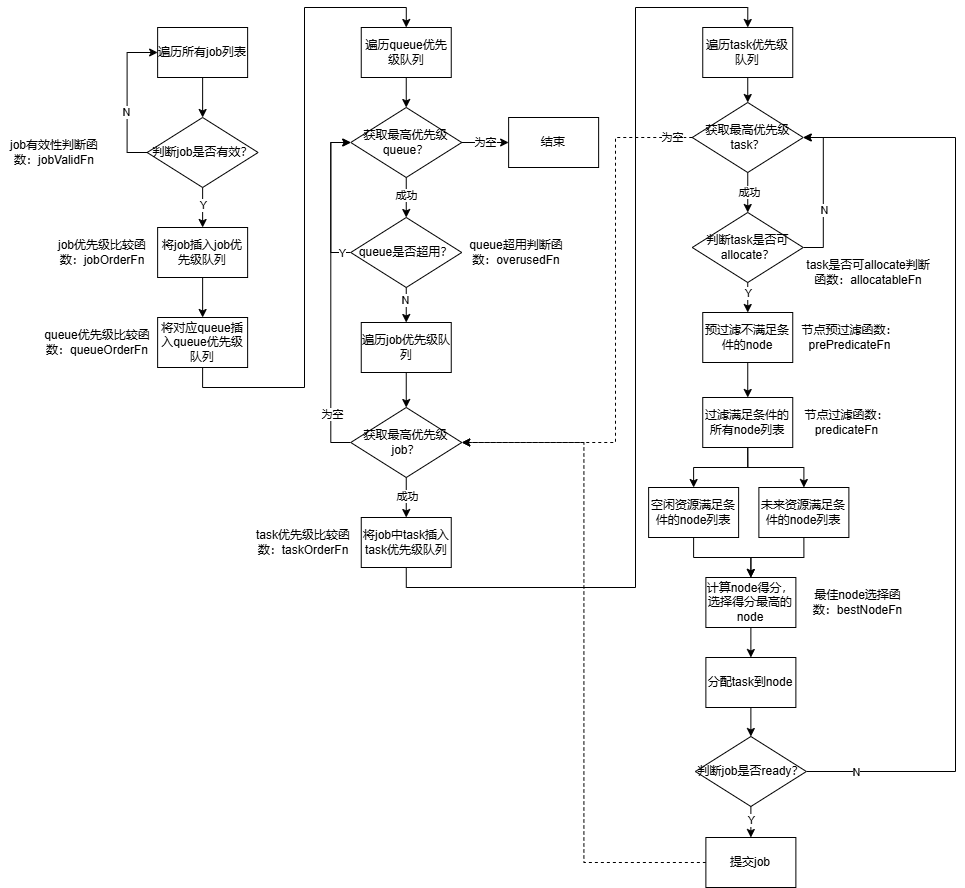
执行步骤:
(1)遍历当前集群中所有job,将有效job加入待处理优先级队列中;
(2)依次获取高优先级queue,并从queue中依次获取高优先级job,将job中Pending状态的task加入优先级队列中;
(3)遍历task优先级队列,过滤出满足运行task的node列表,列表分为两类:当前空闲资源满足条件的node、未来资源满足条件的node。未来资源计算规则为:当前空闲资源+即将释放的资源-pipeline状态等待的资源;
(4)根据node列表,分别计算node得分,选择最佳node,两类node列表优先选择第一类;
(5)分配task到最佳node上;
(6)判断job是否ready,如果ready则提交job,有未处理完的task在下一轮job迭代继续处理,如果未ready继续task迭代。
涉及相关插件如下:
(1)job有效性判断函数jobValidFn,注册的插件有:gang。
(2)queue优先级比较函数queueOrderFn,注册的插件有:capacity、drf、proportion。
(3)job优先级比较函数jobOrderFn,注册的插件有:drf、gang、priority、sla、tdm。
(4)queue超用判断函数overusedFn,注册的插件有:proportion。
(5)task优先级比较函数taskOrderFn,注册的插件有:priority、topology。
(6)allocate判断函数allocatableFn,注册的插件有:capacity、proportion。
(7)预过滤函数prePredicateFn,注册的插件有:predicates。
(8)node批量计算得分函数batchNodeOrderFn,注册的插件有:nodeorder、numaaware。
(9)node计算得分函数nodeOrderFn,注册的插件有:binpack、deviceshare、nodegroup、nodeorder、topology、tdm、usage。
(10)job是否ready判断函数jobReadyFn,注册的插件有:gang。
(11)job是否处于pipelined状态判断函数jobPipelinedFn,注册的插件有:gang、sla、tdm。
(12)node过滤函数predicateFn,注册的插件有:deviceshare、extender、nodegroup、numaaware、predicates、tdm、usage。
5.3 preempt
preempt用于同一queue内部task之间的抢占,主要分为两类:同一queue不同job的task之间抢占、同一job不同task之间抢占。
执行流程图如下:
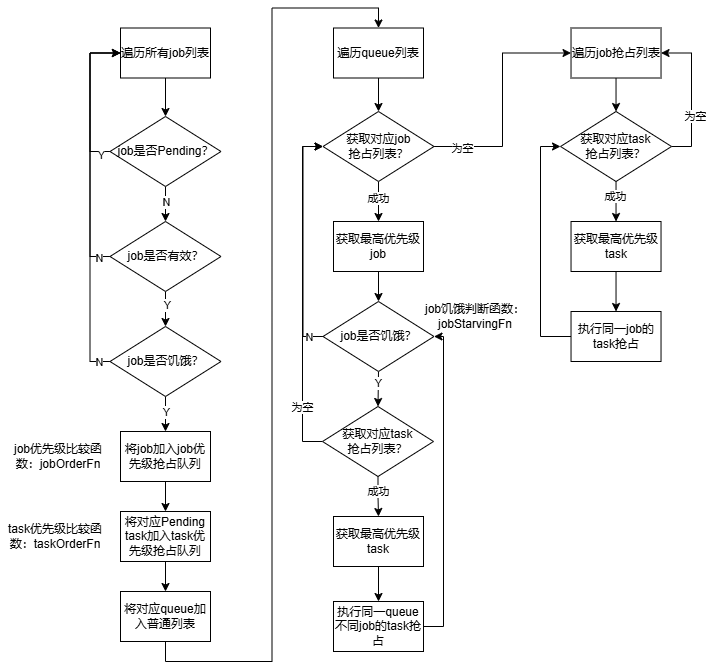
具体抢占流程:
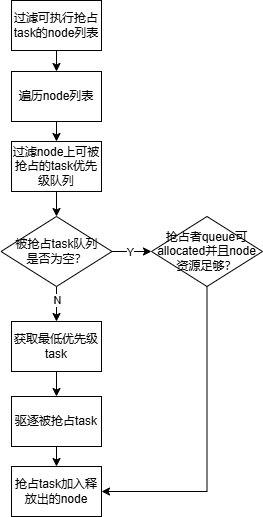
执行步骤:
(1)遍历当前集群中所有job,过滤Pending、有效、饥饿的job加入job优先级抢占队列中,并将对应Pending task加入task优先级抢占队列;
(2)遍历job对应queue列表;
(3)第一阶段:获取queue对应的job优先级抢占队列;
(4)获取最高优先级job,并获取对应task优先级抢占队列;
(5)获取最高优先级task,执行同一queue、不同job的task之间抢占,直到当前job处理完成;
(6)处理完当前queue中所有job,进入第二阶段;
(7)第二阶段:遍历job抢占队列,并获取对应task优先级抢占队列;
(8)获取最高优先级task,执行同一job不同task之间抢占,直到当前job处理完成;
(9)处理完所有job进入(2)。
涉及相关插件如下:
(1)job有效性判断函数jobValidFn,注册的插件有:gang。
(2)job是否饥饿判断函数jobStarvingFn,注册的插件有:tdm、gang、priority。
(3)job优先级比较函数jobOrderFn,注册的插件有:drf、gang、priority、sla、tdm。
(4)task优先级比较函数taskOrderFn,注册的插件有:priority、topology。
(5)job是否处于pipelined状态判断函数jobPipelinedFn,注册的插件有:gang、sla、tdm。
(6)预过滤函数prePredicateFn,注册的插件有:predicates。
(7)node过滤函数predicateFn,注册的插件有:deviceshare、extender、nodegroup、numaaware、predicates、tdm、usage。
(8)node批量计算得分函数batchNodeOrderFn,注册的插件有:nodeorder、numaaware。
(9)node计算得分函数nodeOrderFn,注册的插件有:binpack、deviceshare、nodegroup、nodeorder、topology、tdm、usage。
(10)task抢占判断函数preemptableFn,注册的插件有:cdp、conformance、drf、extender、gang、pdb、priority、tdm。
(11)allocate判断函数allocatableFn,注册的插件有:capacity、proportion。
(12)获取被抢占task列表函数victimTasksFn,注册的插件有:pdb、rescheduling、tdm。
5.4 reclaim
reclaim用于不同queue之间task的抢占,回收部分queue超用的资源。
执行流程图如下:
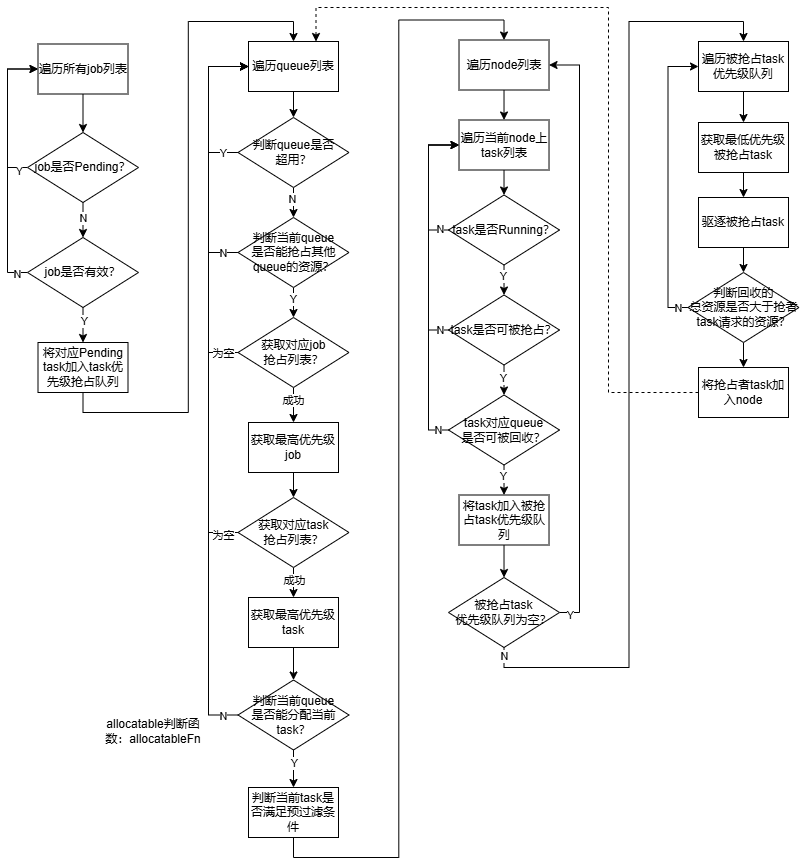
执行步骤:
(1)遍历当前集群中所有job,过滤Pending、有效的job加入job优先级抢占队列中,并将对应Pending task加入task优先级抢占队列;
(2)依次获取高优先级queue,判断queue是否未超用、是否能抢占其他queue资源,两者都满足则继续,否则获取下一queue;
(3)获取queue对应的job优先级抢占队列;
(4)获取最高优先级job,并获取对应task优先级抢占队列;
(5)获取最高优先级task;
(6)遍历当前集群中所有node,过滤Running、可抢占、对应queue(与抢占者task不同queue)可会回收的task加入被抢占task优先级队列;
(7)遍历被抢占task优先级队列,依次获取最低优先级task执行抢占操作,直到释放资源满足抢占者task的请求资源;
(8)进行(4)迭代,结束后进行(2)迭代。
涉及相关插件如下:
(1)job有效性判断函数jobValidFn,注册的插件有:gang。
(2)queue优先级比较函数queueOrderFn,注册的插件有:capacity、drf、proportion。
(3)job优先级比较函数jobOrderFn,注册的插件有:drf、gang、priority、sla、tdm。
(4)task优先级比较函数taskOrderFn,注册的插件有:priority、topology。
(5)queue超用判断函数overusedFn,注册的插件有:proportion。
(6)queue是否可抢占其他queue资源判断函数preemptiveFn,注册的插件有:capacity。
(7)allocate判断函数allocatableFn,注册的插件有:capacity、proportion。
(8)预过滤函数prePredicateFn,注册的插件有:predicates。
(9)node过滤函数predicateFn,注册的插件有:deviceshare、extender、nodegroup、numaaware、predicates、tdm、usage。
(10)过滤被抢占task函数reclaimableFn,注册的插件有:capacity、conformance、drf、extender、gang、pdb、proportion。
5.5 backfill
backfill为BestEffort任务(未指定资源申请量)分配资源。
执行流程图如下:
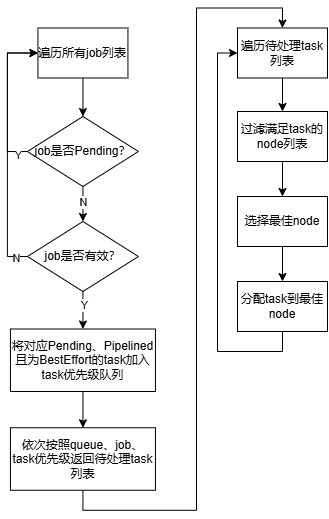
执行步骤:
(1)遍历当前集群中所有job,过滤Pending、有效的job,将对应Pending、Pipelined且为BestEffort的task加入task列表,列表依次按照queue、job、task优先级排序;
(2)遍历task列表,过滤满足task运行的node列表;
(3)选择最佳node,分配task执行;
(4)进行(2)迭代。
涉及相关插件如下:
(1)node过滤函数predicateFn,注册的插件有:deviceshare、extender、nodegroup、numaaware、predicates、tdm、usage。
(2)预过滤函数prePredicateFn,注册的插件有:predicates。
(3)node批量计算得分函数batchNodeOrderFn,注册的插件有:nodeorder、numaaware。
(4)node计算得分函数nodeOrderFn,注册的插件有:binpack、deviceshare、nodegroup、nodeorder、topology、tdm、usage。
(5)job有效性判断函数jobValidFn,注册的插件有:gang。
(6)queue优先级比较函数queueOrderFn,注册的插件有:capacity、drf、proportion。
(7)job优先级比较函数jobOrderFn,注册的插件有:drf、gang、priority、sla、tdm。
(8)task优先级比较函数taskOrderFn,注册的插件有:priority、topology。
6、Plugin
6.1 gang
gang插件用于在分配资源时判断job最小资源或task有效数量是否满足,从而实现All or nothing效果。
6.1.1 数据结构
type gangPlugin struct {
pluginArguments framework.Arguments //插件参数
}
6.1.2 插件初始化
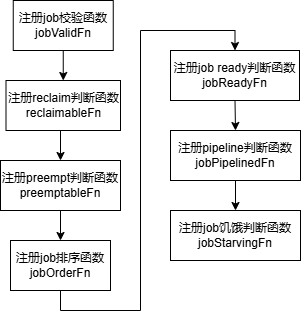
插件初始化主要是注册各种处理函数。
6.1.3 插件后处理
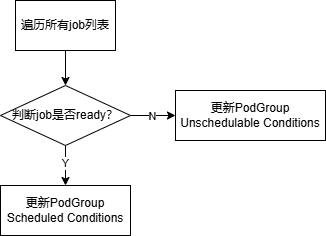
插件后处理主要是更新PodGroup的状态信息。
6.1.4 回调函数
(1)job有效性校验函数jobValidFn
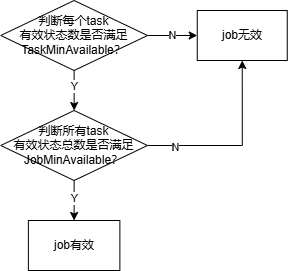
(2)reclaim、preempt判断函数reclaimableFn、preemptableFn
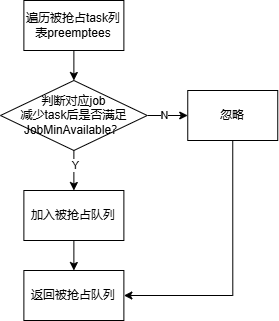
(3)job排序函数jobOrderFn
按照两个job是否ready进行排序,调用job的IsReady函数,参考4.6节。
(4)job是否ready判断函数jobReadyFn
调用job的CheckTaskReady、IsReady函数,参考4.6节。
(5)job是否处于pipelined状态判断函数jobPipelinedFn
调用job的CheckTaskPipelined、IsPipelined函数,参考4.6节。
(6)job是否饥饿判断函数jobStarvingFn
调用job的IsStarving函数,参考4.6节。
6.1.5 插件配置
tiers: - plugins: - name: gang enablePreemptable: false
6.2 binpack
binpack插件通过节点上资源使用率计算节点优先级,资源使用率越高优先级越高,从而达到资源集中分配,减少碎片化的目的,另外计算优先级时还加上不同类型资源的权重系数,来区分资源对优先级的影响大小。
6.2.1 数据结构
type priorityWeight struct {
BinPackingWeight int //binpack插件影响node分值的权重
BinPackingCPU int //CPU权重
BinPackingMemory int //内存权重
BinPackingResources map[v1.ResourceName]int //其他自定义资源权重
}
type binpackPlugin struct {
weight priorityWeight //插件权重参数
}
6.2.2 插件初始化
binpack插件初始化主要包括:解析资源权重参数、注册node分值计算函数nodeOrderFn。
6.2.3 回调函数
(1)node分值计算函数nodeOrderFn
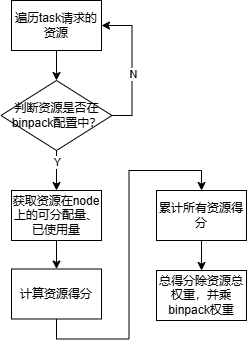
资源得分计算规则:资源权重*({请求量}+{已使用量})/{可分配量},
({请求量}+{已使用量})/{可分配量}表示node的资源使用率越高,分值越大,即任务会优先调度到使用率高的机器上。资源权重表示不同资源类型对得分影响大小。
6.2.4 插件配置
tiers: - plugins: - name: binpack arguments: binpack.weight: 10 binpack.cpu: 5 binpack.memory: 1 binpack.resources: nvidia.com/gpu, example.com/foo binpack.resources.nvidia.com/gpu: 2 binpack.resources.example.com/foo: 3
6.3 priority
priority插件根据任务设置的优先级参数注册任务比较函数,用于优先级队列排序。在集群中可以提前创建多个kind为PriorityClass的优先级对象,每个对象的value表示优先级,值越大,优先级越高,创建任务时指定priorityClassName为某个对象名称。如下为系统默认创建的优先级资源:

6.3.1 数据结构
type priorityPlugin struct {
pluginArguments framework.Arguments
}
6.3.2 插件初始化
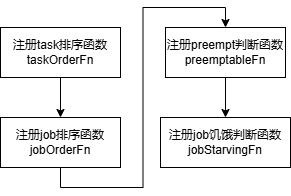
6.3.3 回调函数
(1)task排序函数taskOrderFn
按照两个task的优先级参数进行排序,值越大优先级越高。
(2)job排序函数jobOrderFn
安装两个job的优先级参数进行排序,值越大优先级越高。
(3)preempt判断函数preemptableFn
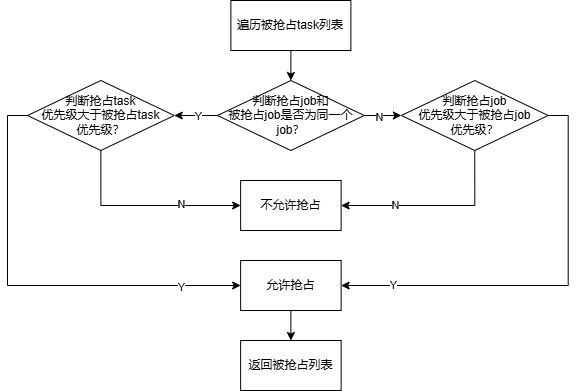
(4)判断job饥饿函数jobStarvingFn
比较job.ReadyTaskNum()+job.WaitingTaskNum()是否小于len(job.Tasks),小于说明job饥饿。
6.3.4 插件配置
tiers: - plugins: - name: priority
6.4 drf
drf插件通过job的主导资源来进行任务调度,根据主导资源计算job的share值,计算规则为share=max({资源1已分配量}/{资源1总量}, {资源2已分配量}/{资源2总量}, ...),share值越小,表示job占用资源越少,优先级越高,这种策略可以防止小任务过度饥饿。
6.4.1 数据结构
//每个job的资源属性
type drfAttr struct {
share float64 //遍历所有资源,计算job.allocated/ssn.totalResource,获取比值最大者为share,即每个job的主导资源,用于job优先级排序,share值越小,表示job资源占用越少,优先级越高
dominantResource string //job的主导资源名
allocated *api.Resource //job中所有已分配状态task的Resreq总量,已分配状态包括:Bound、Binding、Running、Allocated
}
type drfPlugin struct {
totalResource *api.Resource //集群资源总量
totalAllocated *api.Resource //资源总分配量
jobAttrs map[api.JobID]*drfAttr //所有任务资源属性
hierarchicalRoot *hierarchicalNode //分层结构根节点
pluginArguments framework.Arguments
}
6.4.2 插件初始化

6.4.3 回调函数
(1)preempt判断函数preemptableFn
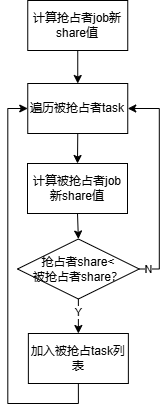
执行流程:
- 计算抢占者job新的share值,计算规则为:(job.allocated + task.Resreq)/ssn.totalResource;
- 遍历被抢占者task列表,计算被抢占者job新的share值,计算规则为:(job.allocated - task.Resreq)/ssn.totalResource;
- 比较抢占者job新share值和被抢占者job新share值,如果前者小于后者,则被抢占者可被抢占;
- 返回被抢占者task列表。
(2)job排序函数jobOrderFn
比较两个job的share值,值越小,优先级越高。
(3)事件处理函数eventHandlers
注册资源分配AllocateFunc、资源释放DeallocateFunc处理函数,函数中更新job的share值。
6.4.4 插件配置
tiers: - plugins: - name: drf
6.5 proportion
proportion插件根据queue的配置将集群资源按比例分配到不同queue。
6.5.1 数据结构
//每个队列的资源属性
type queueAttr struct {
queueID api.QueueID //queue uid
name string //queue名称
weight int32 //queue权重
share float64 //遍历queue中所有资源,计算allocated/deserved,获取比值最大者为share,用于queue优先级排序,值越小,表示资源占用越少,优先级越高
deserved *api.Resource //应分配资源量
allocated *api.Resource //已分配资源量
request *api.Resource //请求资源量
elastic *api.Resource //弹性资源量,每个job的弹性资源为job.allocated-job.minAvailable
inqueue *api.Resource //inqueue job的请求资源量
capability *api.Resource //queue设置的资源容量
realCapability *api.Resource //实际资源容量,集群总容量减去其他队列预留资源总量,并且不超过capability
guarantee *api.Resource //预留资源量
}
type proportionPlugin struct {
totalResource *api.Resource //集群资源总量
totalGuarantee *api.Resource //资源预留总量
queueOpts map[api.QueueID]*queueAttr //各队列资源使用情况
pluginArguments framework.Arguments
}
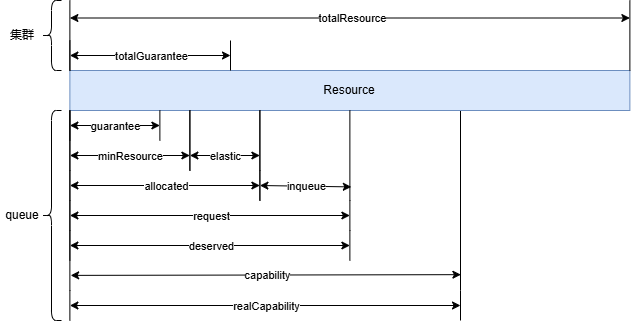
proportion插件各字段含义及计算规则如下:
(1)totalResource:proportion插件属性,表示集群资源总量,将所有节点资源累加。
(2)totalGuarantee:proportion插件属性,表示资源预留总量,将所有queue配置的guarantee累加。
(3)capability:queue属性,表示容量上限,在queue配置中设置。
(4)guarantee:queue属性,表示queue配置的预留量。
(5)realCapability:queue属性,表示实际容量上限,不大于capability,取值:min(capability, totalResource-totalGuarantee+guarantee)。
(6)allocated:queue属性,表示已分配资源总量,需要遍历queue中所有状态为Bound, Binding, Running, Allocated的task的资源请求量。
(7)request:queue属性,表示资源请求总量,需要遍历queue中所有状态为Bound, Binding, Running, Allocated, Pending的task的资源请求量。
(8)deserved:queue属性,表示按队列权重比例应分配的资源量,不大于realCapability、request。
(9)elastic:queue属性,表示弹性资源,由queue中所有任务的allocated减所有任务的minResource。
(10)inqueue:queue属性,当queue中job为inqueue状态时,取值为任务的minResource,当queue中job为running状态时,取值为任务的max(0, minResource-allocated)。
比例图如下:
6.5.2 插件初始化
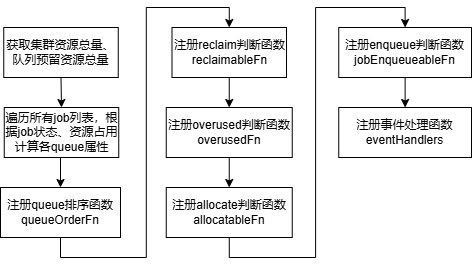
6.5.3 回调函数
(1)queue排序函数queueOrderFn
按照两个queue的share值进行排序,值越小优先级越高。
(2)reclaim判断函数reclaimableFn

(3)overused判断函数overusedFn
根据比较queue的deserved、allocated来判断队列是否超用,如果allocated>=deserved,则表示超用,否则没有。
(4)allocate判断函数allocatableFn
计算queue的空闲资源量free=deserved-allocated,当待分配的task.Resreq<=free时,则表示可分配,否则不可。
(5)enqueue判断函数jobEnqueueableFn
计算job入队后的最小资源总量totalMinResource=job.minResource + queue.allocated + queue.inqueue - queue.elastic,如果totalMinResource<=queue.realCapability,表示资源满足需求可入队,否则不可入队。
(6)事件处理函数eventHandlers
注册资源分配AllocateFunc、资源释放DeallocateFunc处理函数。资源分配时,增加对应queue的allocated,增量为task.Resreq,同时更新queue的share。资源释放时,减少对应queue的allocated,减少量为task.Resreq,同时更新queue的share。
6.5.4 插件配置
tiers: - plugins: - name: proportion
6.6 predicates
predicate插件用于过滤运行pod的节点。
6.6.1 数据结构
type baseResource struct {
CPU float64
Memory float64
}
type predicateEnable struct {
nodeAffinityEnable bool
nodePortEnable bool
taintTolerationEnable bool
podAffinityEnable bool
nodeVolumeLimitsEnable bool
volumeZoneEnable bool
podTopologySpreadEnable bool
cacheEnable bool
//是否启用资源比率判断,启用的资源由predicate.resources设置,值为逗号分隔的资源名列表,如:nvidia.com/gpu
proportionalEnable bool
//启用资源比率判断时,各资源对应的CPU、Memory值,如:ResourceName为nvidia.com/gpu,baseResource.CPU为4,baseResource.Memory为8时,表示每个GPU实例,至少需要分配4个CPU和至少8G内存。但实际源码中函数checkNodeResourceIsProportional计算cpuReserved、memoryReserved时需要分别乘1000才表示核数、GB,当前源码分别表示1/1000核数、MB
proportional map[v1.ResourceName]baseResource
}
type predicatesPlugin struct {
pluginArguments framework.Arguments
}
6.6.2 插件初始化
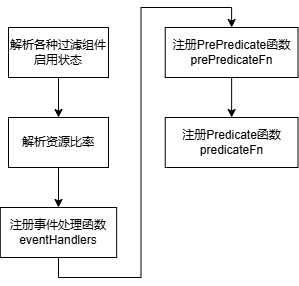
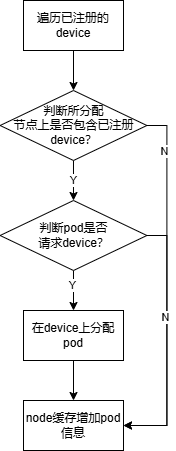
(2)资源释放处理函数DeallocateFunc
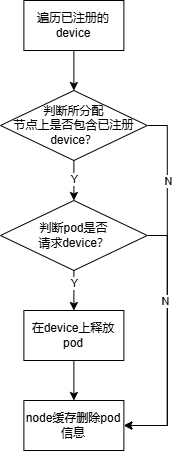
(3)预过滤函数prePredicateFn
用于判断task对应pod的container port、亲和性、拓扑是否满足条件。
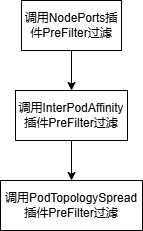
(4)过滤函数predicateFn
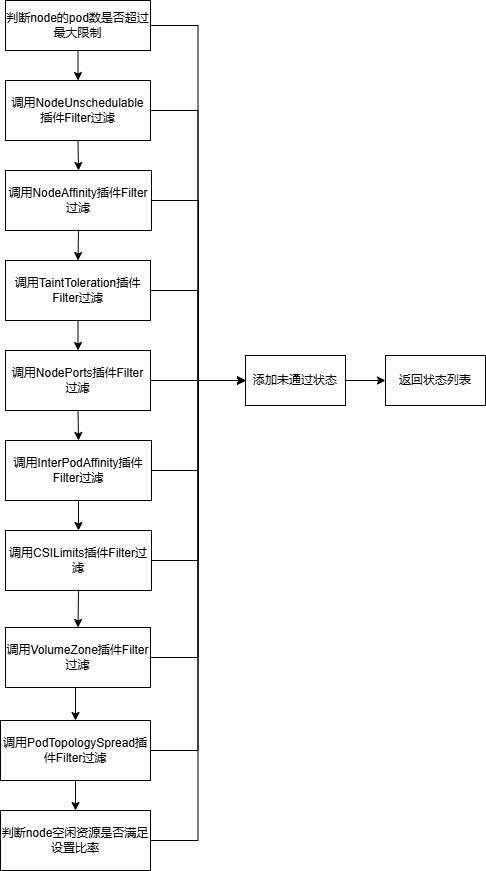
6.6.4 插件配置
tiers:
- plugins:
- name: predicates
arguments:
predicate.NodeAffinityEnable: true
predicate.NodePortsEnable: true
predicate.TaintTolerationEnable: true
predicate.PodAffinityEnable: true
predicate.NodeVolumeLimitsEnable: true
predicate.VolumeZoneEnable: true
predicate.PodTopologySpreadEnable: true
predicate.GPUSharingEnable: true
predicate.GPUNumberEnable: true
predicate.CacheEnable: true
predicate.ProportionalEnable: true
predicate.resources: nvidia.com/gpu
predicate.resources.nvidia.com/gpu.cpu: 4
predicate.resources.nvidia.com/gpu.memory: 8
6.7 nodeorder
nodeorder插件用于根据用户配置的权重对节点进行排序。
6.7.1 数据结构
type priorityWeight struct {
leastReqWeight int
mostReqWeight int
nodeAffinityWeight int
podAffinityWeight int
balancedResourceWeight int
taintTolerationWeight int
imageLocalityWeight int
podTopologySpreadWeight int
}
type nodeOrderPlugin struct {
pluginArguments framework.Arguments
}
6.7.2 插件初始化
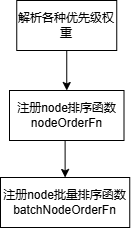
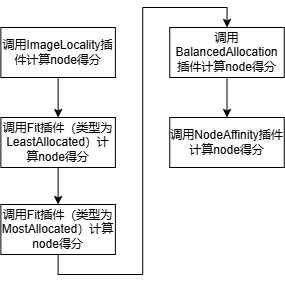
LeastAllocated插件计算规则:
节点得分=((cpu空闲量*节点最大得分/cpu总容量)*cpu权重 + (内存空闲量*节点最大得分/内存总容量)*内存权重)/总权重
=((cpu空闲量*100/cpu总容量)*50 + (内存空闲量*100/内存总容量)*50)/100
含义:资源空闲量越大,节点得分越高,优先级越高。
MostAllocated插件计算规则:
节点得分=((cpu请求量*节点最大得分/cpu总容量)*cpu权重 + (内存请求量*节点最大得分/内存总容量)*内存权重)/总权重
=((cpu请求量*100/cpu总容量)*1 + (内存请求量*100/内存总容量)*1)/2
含义:资源请求量越大,节点得分越高,优先级越高。
BalancedAllocation插件计算规则:
节点得分=(1-std)*节点最大得分
=(1-std)*100
其中:
std=sqrt(Σ((fraction(i)-mean)^2)/len(resources))
fraction(i)=第i个资源的请求量/第i个资源的总容量
mean=所有fraction的平均值
含义:资源使用量差值越小,使用量越均衡,节点得分越高,优先级越高。
(2)node批量计算得分函数batchNodeOrderFn
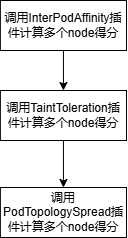
InterPodAffinity、TaintToleration、PodTopologySpread分别调用PreScore、Score、NormalizeScore计算多个节点的得分。
6.7.4 插件配置
tiers:
- plugins:
- name: nodeorder
arguments:
leastrequested.weight: 1
mostrequested.weight: 0
nodeaffinity.weight: 2
podaffinity.weight: 2
balancedresource.weight: 1
tainttoleration.weight: 3
imagelocality.weight: 1
podtopologyspread.weight: 2
6.8 nodegroup
nodegroup插件用于根据节点标签分组,以及queue中节点组的亲和性配置对节点进行排序和过滤。
6.8.1 数据结构
type queueGroupAffinity struct {
queueGroupAntiAffinityRequired map[string]sets.Set[string]
queueGroupAntiAffinityPreferred map[string]sets.Set[string]
queueGroupAffinityRequired map[string]sets.Set[string]
queueGroupAffinityPreferred map[string]sets.Set[string]
}
type nodeGroupPlugin struct {
pluginArguments framework.Arguments
}
6.8.2 插件初始化
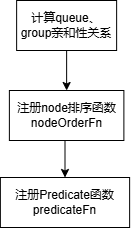
6.8.3 回调函数
(1)node排序函数nodeOrderFn
通过给节点打volcano.sh/nodegroup-name标签将节点进行分组,然后根据queue设置的NodeGroup亲和性、反亲和性计算每个节点的得分。
计算规则为:满足Required亲和性时得分加100,满足Preferred亲和性时得分加50,满足Preferred反亲和性时得分减1。
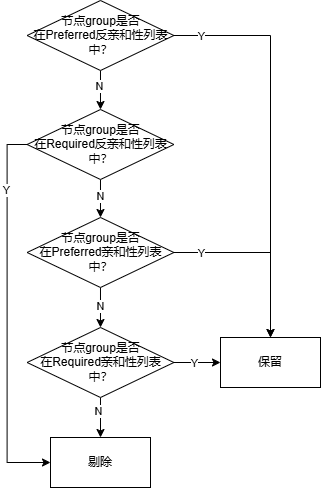
(2)过滤函数predicateFn
根据节点分组,以及queue设置的NodeGroup亲和性、反亲和性过滤每个节点。
判断规则按优先级依次为:满足Preferred反亲和性时节点保留,满足Required反亲和性时节点剔除,满足Preferred亲和性时节点保留,满足Required亲和性时节点保留。
6.8.4 插件配置
tiers: - plugins: - name: nodegroup
6.9 capacity
capacity插件与proportion插件类似,区别在于capacity通过直接设置deserved值,而proportion通过设置weight来自动计算deserved值,两者不可同时使用。
6.10 conformance
conformance插件用于防止抢占和回收一些重要的系统任务。
6.10.1 数据结构
type conformancePlugin struct {
pluginArguments framework.Arguments
}
6.10.2 插件初始化
conformance插件初始化包括:注册reclaim判断函数reclaimableFn、注册preempt判断函数preemptableFn。
6.10.3 回调函数
(1)reclaim、preempt判断函数preemptableFn、reclaimableFn
判断task是否可以被抢占和回收,如果task对应pod的priorityClassName是system-cluster-critical、system-node-critical,或者namespace是kube-system,则task不允许被抢占和回收。
6.10.4 插件配置
tiers: - plugins: - name: conformance
6.11 overcommit
overcommit插件用于控制集群资源的超用比率,允许提交超过集群实际资源的任务量。
6.11.1 数据结构
type overcommitPlugin struct {
pluginArguments framework.Arguments //插件参数
totalResource *api.Resource //总资源
idleResource *api.Resource //空闲资源
inqueueResource *api.Resource //inqueue资源
overCommitFactor float64 //超用比率,必须大于1,默认为1.2
}
6.11.2 插件初始化
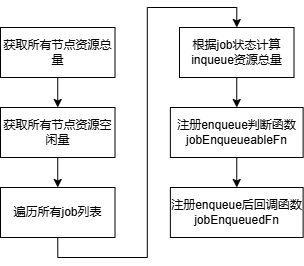
6.11.3 回调函数
(1)enqueue判断函数jobEnqueueableFn
在enqueue Action阶段判断job是否可入队。当job的MinResources加上当前inqueue资源总量超过空闲资源总量时,不允许入队,否则允许。
(2)enqueue后回调函数jobEnqueuedFn
在job enqueue后,调用回调函数更新inqueue资源总量。
6.11.4 插件配置
tiers: - plugins: - name: overcommit arguments: overcommit-factor: 1.0
6.12 sla
sla插件用于设置job的等待时间,通过等待时间对job进行优先级排序,防止job过度饥饿。
6.12.1 数据结构
type slaPlugin struct {
pluginArguments framework.Arguments //插件参数
jobWaitingTime *time.Duration //job被inqueue的最大等待时间
}
6.12.2 插件初始化
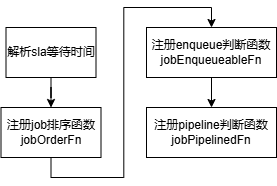
6.12.3 回调函数
(1)job排序函数jobOrderFn
比较两个job的等待截止时间,即CreationTimestamp+WaitingTime,按照该值大小排序,值越小优先级越高,可用于防止任务处于过度饥饿状态。
(2)enqueue判断函数jobEnqueueableFn
在enqueue Action阶段判断job是否可入队。当job处于pending的时间超过设置的最大等待时间WaitingTime时,job会被判断可inqueue,否则sla插件会放弃判断。
(3)pipeline状态判断函数jobPipelinedFn
在allocate Action阶段判断job是否可进入pipeline状态等待释放中的资源,同jobEnqueueableFn。
6.12.4 插件配置
设置全局最大等待时间
tiers:
- plugins:
- name: sla
arguments:
sla-waiting-time: 1h2m3s4ms5µs6ns
设置指定job等待时间
kind: Job metadata: annotations: sla-waiting-time: 1h2m3s4ms5us6ns
7、功能扩展
Volcano二次开发涉及到扩展Action、Plugin,本文接下来主要介绍如何进行功能扩展。演示的功能为:选择pod数量最少的节点进行调度,
7.1 Action扩展
(1)在scheduler/actions目录中创建launch/launch.go,代码如下:
package launch
import (
"k8s.io/klog/v2"
"volcano.sh/volcano/pkg/scheduler/api"
"volcano.sh/volcano/pkg/scheduler/framework"
)
type Action struct {
session *framework.Session
}
func New() *Action {
return &Action{}
}
func (launch *Action) Name() string {
return "launch"
}
func (launch *Action) Initialize() {}
func (launch *Action) Execute(ssn *framework.Session) {
klog.V(5).Infof("Enter Launch ...")
defer klog.V(5).Infof("Leaving Launch ...")
stmt := framework.NewStatement(ssn)
for _, job := range ssn.Jobs {
if vr := ssn.JobValid(job); vr != nil && !vr.Pass {
continue
}
for _, task := range job.TaskStatusIndex[api.Pending] {
selectNode := launch.choseNode(ssn)
if err := stmt.Allocate(task, selectNode); err != nil {
_ = stmt.UnAllocate(task)
}
}
if ssn.JobReady(job) {
stmt.Commit()
}
}
}
// select node has minimum pod number
func (launch *Action) choseNode(ssn *framework.Session) *api.NodeInfo {
var selectNode *api.NodeInfo
taskNum := -1
for _, node := range ssn.NodeList {
if taskNum == -1 || len(node.Tasks) < taskNum {
taskNum = len(node.Tasks)
selectNode = node
}
}
return selectNode
}
func (launch *Action) UnInitialize() {}
(2)在scheduler/actions/factory.go中增加:
framework.RegisterAction(launch.New())
(3)调度服务配置如下:
actions: "enqueue, launch" tiers: - plugins: - name: proportion
(4)创建第一个验证服务:
kubectl apply -f nginx-1.yaml
yaml内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-1
namespace: default
labels:
app: nginx-1
spec:
replicas: 1
selector:
matchLabels:
app: nginx-1
template:
metadata:
labels:
app: nginx-1
spec:
schedulerName: volcano
containers:
- name: nginx-1
image: docker.io/library/nginx:1.25
imagePullPolicy: IfNotPresent
ports:
- containerPort: 81
---
apiVersion: v1
kind: Service
metadata:
name: nginx-1
namespace: default
spec:
type: NodePort
selector:
app: nginx-1
ports:
- port: 81
targetPort: 81
nodePort: 30201
启动调度前:

启动调度后:

(5)创建第二个验证服务:
kubectl apply -f nginx-2.yaml
yaml内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-2
namespace: default
labels:
app: nginx-2
spec:
replicas: 1
selector:
matchLabels:
app: nginx-2
template:
metadata:
labels:
app: nginx-2
spec:
schedulerName: volcano
containers:
- name: nginx-2
image: docker.io/library/nginx:1.25
imagePullPolicy: IfNotPresent
ports:
- containerPort: 82
---
apiVersion: v1
kind: Service
metadata:
name: nginx-2
namespace: default
spec:
type: NodePort
selector:
app: nginx-2
ports:
- port: 82
targetPort: 82
nodePort: 30202
启动调度前:

启动调度后:

